As part of a migration from an old monolith to a microservices architecture, another team in my company was backfilling historical data by publishing kafka messages to a topic. I was in charge of another microservice which was also consuming from this same topic. Normally, during regular traffic, we were dealing with around 1-2 msgs/s. And no more than 5 msgs/s. With our setup, which included 3 consumers (1 per partition), we were able to process up to ~16.5 msgs/s (we learned this only later on).
TL;DR: Consume and process in batches to make your consumers faster.
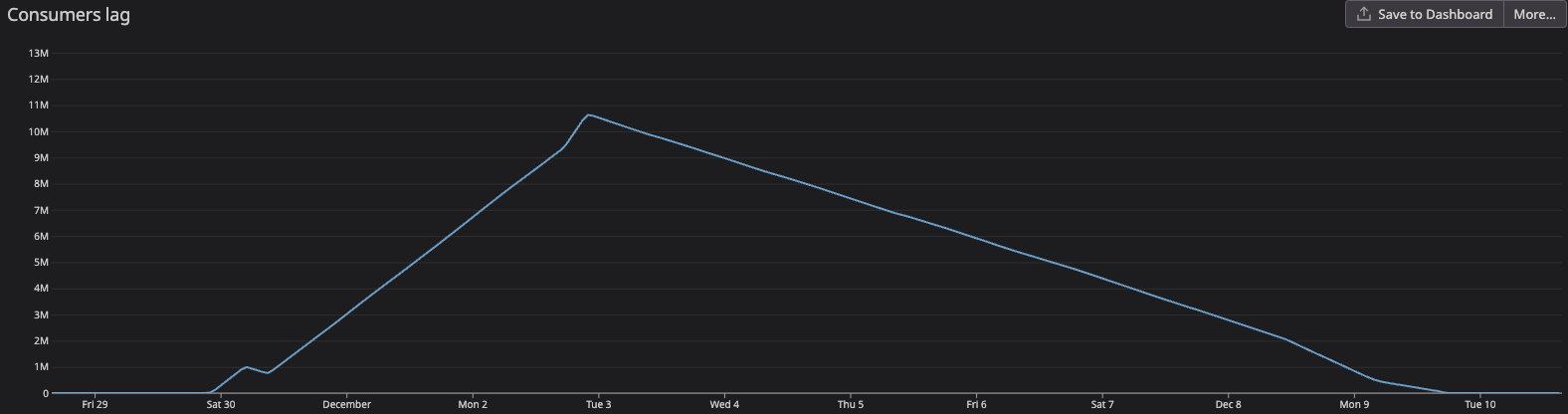
During the backfill the kafka topic received A LOT of messages. ~14.5 million messages were created within a day and a half, a third of them (~5M) were produced within 3 hours. If you do the math, on average that is ~110 msgs/s, and during the peak it was more like ~450 msgs/s. With a consumption rate of 16.5 msgs/s, processing it takes a long time. Like 10 days long 😓. This caused a huge lag, of course. Any newly published messages would have to wait in the queue. Luckily, although this happened in production, no users were using the service yet.
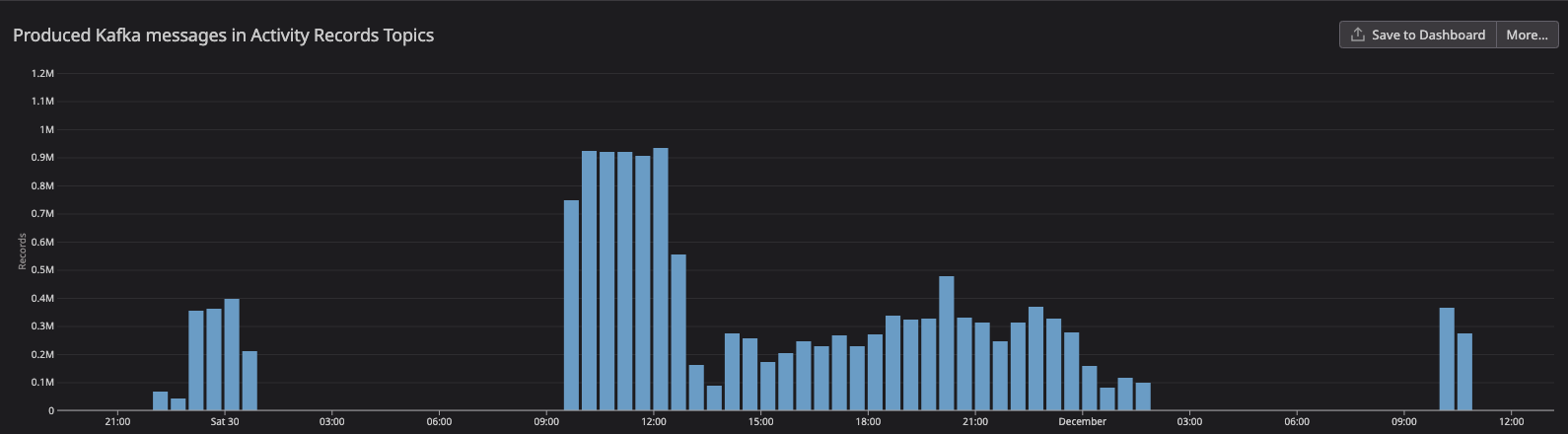
Investigation
We needed to find a way to speed things up. We noticed that the reason for our slow consumers was that they were saving data synchronously to DynamoDB. The average time to process a message and save it to the db was ~180ms, which fits pretty well with our numbers (1000ms / 180ms = ~5.5 msgs/s. 5.5 * 3 consumers = ~16.5 msgs/s). Root cause identified! Now we need to find a way to mitigate this.
First suspect: process async
I was taught that whenever you are waiting on I/O, it means you should use concurrency. Let’s call DynamoDB async. Boto3 library doesn’t support async, but aioboto3 does! There’s just one problem. Even if we send our requests async, python is not gonna be doing anything else while waiting, because we are only consuming 1 message at a time. To illustrate this, the process would be something like this:
-> consume 1 message
-> send "async" request to dynamodb
-> ready to process any other async job... but there is none ...
-> receive response
-> commit offset to kafka
-> consume 1 message
-> etc...
Kafka consumers consume in order. We use manual commit to avoid losing messages in case of failures (which is not the subject of this post, but you can read more about it here). This slows things down. And doesn’t allow us to utilize concurrency very well.
Second thought: scale consumers horizontally, increase partitions
We have 3 consumers. What if we had more? Let’s just scale the amount of consumers. Unfortunately, that won’t work. Kafka doesn’t play nice with more than 1 consumer per partition. If you have more, it would only allow 1 of them to consume, and the rest would be idle, at the best case, or cause constant rebalances in the worst case (rebalances occur when a consumer is added to a consumer group or when the number of partitions change, it is a costly process that takes quite some time). In other words, parallelism in kafka is ultimately determined by the amount of partitions.
Ok, so let’s increase the number of partitions then!
Pros:
- It would immediately unblock some of the new messages that are produced and land in the new partitions.
- It would allow us to scale to more consumers.
- It would help with future backfills.
Cons:
- Some messages would still land in the laggy partitions.
- It won’t help with the existing lag, because there are already messages in the current partitions, which won’t get redistributed.
- Confluent cloud charge per partitions, and it could get quite expensive.
The cons outweigh the pros, and don’t solve the issue. We are considering perhaps adding a dedicated topic for future backfills, with its own consumers, so that it won’t block production. Honestly, I don’t mind if a backfill is done slowly and takes 10 days as long as it doesn’t block production.
What about Kafka Streams?
We thought maybe we can utilize kafka streams, or a variation of it. Basically, consume all the messages with a new consumer, and all that it would do is forward it back to a new topic with a lot more partitions. The problem: Kafka Streams is only really supported well in Java (which we have no experience with), and it just seemed like an overkill to implement a simple variation of it ourselves.
The Solution: consume and process in batches
So we can’t utilize async properly, and increasing the amount of consumers/partitions won’t help. What else could we do? We are processing 1 message at a time. What if we could process in batches? Luckily, we can! Kafka consumers are able to consume multiple messages at a time (docs), and DynamoDB has batch write functionality (docs). With this setup, we should be able to reduce the processing time by PREVIOUS_RATE x BATCH_SIZE. DynamoDB batch limit is 25, so we decided to go with that and a timeout of 1s. In other words, the consumers would consume up to 25 messages or every 1 second, whichever comes first. That should reduce a future similar spike from ~10 days to ~10 hours ( ~410 msgs/s), while also keeping the normal traffic relatively quick. This does introduce a slight 1s latency to users down the line, but is totally acceptable in an async environment. If this would ever be a problem in the future, we could improve this by decreasing the timeout period, or the batch size, or both. They are all controlled by environment variables, so it’s an easy change.
It took us a few days to realize the problem, find the root cause, decide on a solution and deploy it, but we were able to do so in the final hours of the lag. You can see the results for yourself. If we weren’t to deploy our solution, at the rate it was going, it would have taken ~3 hours to finish consuming. Instead, it only took 3 minutes! That is a rate of about 330 msgs/s. I believe that it took some time for all consumers to deploy, and it is likely that if it would have run for a longer period of time we would have seen that it reaches closer to ~410 msgs/s as I calculated above.
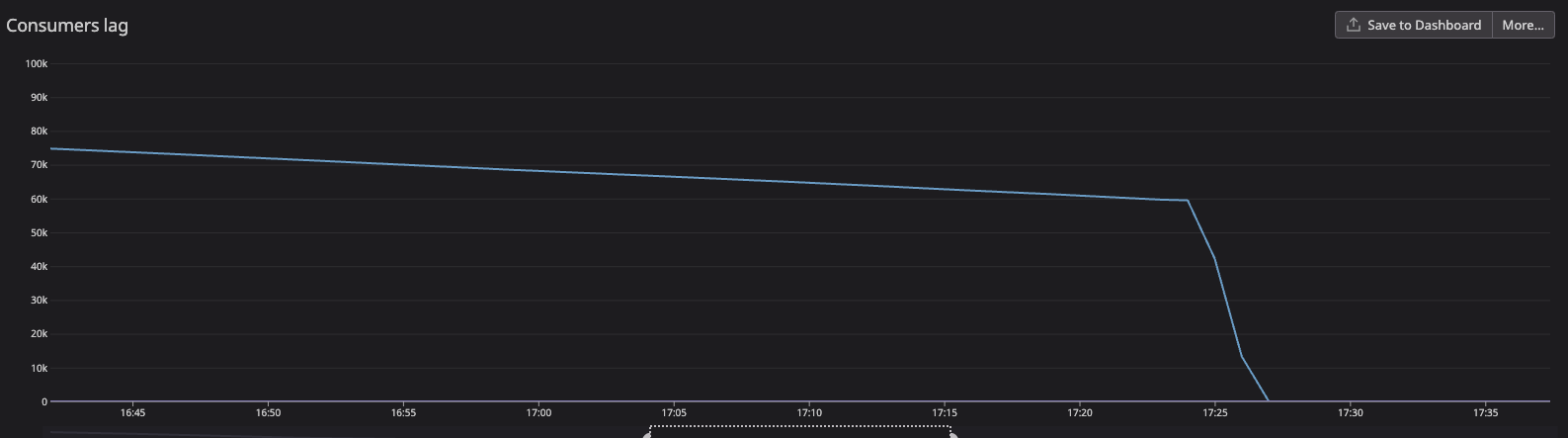
Error handling
Usually it is best practice to send failed messages into a DLQ (dead letter queue). In our use case, we just log errors and have alerts in place. We can then reprocess a specific message if needed (with our dedicated replay consumer), because our service is idempotent. When dealing with batches, it is important to handle errors correctly, so that you don’t miss failures. This is true for any consumer, but may be more difficult with batches. This is not the topic of the post, but I thought it should be mentioned.
How to determine the correct batch configuration for a consumer?
First of all, it really depends on the throughput. Consumers tend to have a relatively stable throughput, with occasional “seasonal” or “weekly” or “daily” spikes, that are relatively manageable, and known in advance. Occasionally, there is a spike that isn’t known ahead of time because of errors with services upstream, backfills, or special “superbowl-like” events with high throughput.
It also depends on the use case. What is the acceptable amount of latency a user can experience? I would argue that for most async use cases, especially machine-to-machine (which are most use cases with kafka), a few milliseconds to seconds is totally acceptable. Backfilling data can usually allow for minutes or even hours or days of lag. But the question is what do you want to optimize for, the normal throughput, or spikes.
Here are a few guidelines:
- Batch-size/timeout should be close to the average-throughput/number-of-partitions. This will maximize throughput and minimize latency.
- If the timeout is too low, the consumer may be laggy, because it won’t consume enough messages in each batch, and they will be waiting. The user experiences this as latency.
- If the batch size is too low, messages will constantly be waiting for more messages to arrive. The user experiences this as latency as well.
- Be careful with a batch size that is too high, because you may run into memory issues (the bigger the batch, the more memory you use).
- If you want to optimize for spikes, increase the batch size.
- Typically (IMHO) a timeout of 1 second is convenient, because it helps with calculations (we usually speak in terms of X messages per 1 second). It is short enough to be considered fast, and long enough to let messages accumulate. Up to you and your use case, really.
- Having the user experience a known constant low latency is usually better than having all users wait because of a sudden unexpected spike. If in doubt, opt for high batch size and low timeout.
Links:
- https://www.groundcover.com/blog/kafka-slow-consumer - this was a very helpful article while solving this issue.